Fictional users that write real reviews
We test SlyReply with a couple of dozen fictional people — AI personas that drive the real product and write honest reviews. Here's how, and why it beats more assertions.
- ai-agents
- testing
- infrastructure
Synthetic checks tell me an endpoint returns 200. End-to-end tests tell me a button I already know about still works. Neither tells me the thing I actually lie awake about: when someone who takes privacy seriously — who reads the policy before signing up and notices whether "reject all" is as easy to find as "accept all" — lands on a product whose entire pitch is we don't read your email, do they come away trusting it, or not?
So I gave that person a name. Rashida is one of a couple of dozen fictional people who test SlyReply by genuinely trying to use it — AI personas that drive the real product end to end and then write an honest, first-person review of what happened. This post is how that works and why it catches things a conventional test suite never will.
The problem with "does it work"
A test asserts a fact you already thought of. The failures that hurt a young product aren't the ones you thought of — they're the moments a real person stalls, misreads a label, distrusts a price, or quietly gives up. You can't expect() your way to those, because if you'd anticipated them you'd have fixed them already.
What I wanted was a tester with opinions — one that reacts the way a specific kind of person actually would, and tells me where it lost them. That's a persona.
A couple of dozen archetypes, deliberately uneven
Each persona is a short brief — a goal, a temperament, a tolerance for friction — that becomes the agent's system prompt, so it reacts in character rather than like a script. They're deliberately not variations on "a user." Each is a single sharp lens, and between them they cover surfaces a homogenous "tester" would smear over:
- Rashida, a privacy skeptic, reads the privacy policy and the cookie banner before she trusts anything;
- Maya, a first-time mobile visitor, is impatient and will bounce if the homepage doesn't hook her in thirty seconds;
- Sasha, a comparison shopper, lands on the pricing page with two competitors open and judges it cold;
- Solomon drives the whole product with a screen reader; Iris uses the keyboard only;
- Dmitri, a security-curious prober, pokes at the edges; Hugo tries reserved names and brand-edge slugs;
- Tomas, a free-to-paid converter, walks the upgrade flow; Aiko tests the declined-card sad path;
- Vita is on a flaky connection; Leila types Unicode into every field; Priya checks the email round-trip actually lands;
…and a couple of dozen more, each activated per run. Between them they walk every flow in the product and surface the copy, UX, trust, pricing, accessibility, internationalisation, billing and abuse problems a single generic tester would miss.
Rashida is the one I pay closest attention to, because she's the customer SlyReply most has to win. When the persona whose entire job is to distrust a privacy product reads the policy, checks where the data goes, and comes away unconvinced, that isn't a failed assertion — it's the most important user I have telling me I haven't earned it yet. That's the finding.
How a run actually works
Each persona run is two passes on the Claude Agent SDK, with a deliberate split of models:
- Explore — a cheaper, faster model (Sonnet) drives a real browser via the Playwright MCP server, plus in-process tools for sending and reading email. It walks the persona's brief, fully in character, and calls a
note_findingtool every time it reacts. - Report — a stronger model (Opus), with no tools, being the persona, writes an honest first-person review from the findings it collected plus a digest of the transcript.
sequenceDiagram
participant P as Persona (explore · Sonnet)
participant B as Real browser + email (Playwright MCP)
participant F as Findings collector
participant R as Review (report · Opus)
participant H as Human (Test Ease UI)
P->>B: sign up, create an agent, send a real email
B-->>P: pages, replies, friction
P->>F: note_finding(kind, severity, title, body)
F->>R: findings + transcript digest
R->>H: first-person review, in the persona's voice
H->>H: triage, then file one GitHub issueOne persona run: explore in character, collect reactions, write the review — then a human decides what's real.
The split matters for cost: the long, many-turn exploration runs on the cheaper model; the one thing that has to be genuinely well-written — the review — gets the expensive one. Model IDs are configuration, and the whole thing runs in an isolated sandbox with its own spend cap, so a runaway loop can't surprise me on the bill.
Findings have a shape
A finding is one structured observation the persona makes mid-run. Early on the schema was just (category, severity), and personas started smuggling compliments in as severity="nit" — which buried real fixables under praise in the "X findings" badge. So findings now carry an orthogonal kind axis:
# Three "fix me" kinds, two that need no fix.
KINDS = ("bug", "gap", "risk", "nit", "praise", "observation")
FIXABLE_KINDS = frozenset({"bug", "gap", "risk", "nit"})
# severity only carries meaning for the fixable kinds;
# praise and observation ignore it.
SEVERITIES = ("blocker", "major", "minor", "nit")The review UI splits on that axis: a 🐞 fix list, a ✓ "working well" section, and 🔎 neutral observations. Keeping praise as a first-class kind matters more than it sounds — it stops the signal ("here are six things to fix") from drowning in the noise of an agent being polite.
The agents never file the issues
This is the most important design decision, so it gets its own heading: the harness never opens a GitHub issue on its own. An LLM will confidently report a bug that isn't one. If that went straight to the tracker, the QA system would generate more work than it saved and I'd stop trusting it inside a week.
Instead every run lands in a small internal review tool — we call it Test Ease — where the findings sit next to each persona's written review. A human reads the review in the persona's voice, triages each finding (keep or dismiss), marks the false positives, and files one issue per run with the kept findings grouped by severity. Triage happens once, centrally, so the same confusion that three personas all tripped over becomes one issue, not three.
The agents are extremely good at noticing. They're not allowed to decide. That line is the whole reason the system is usable.
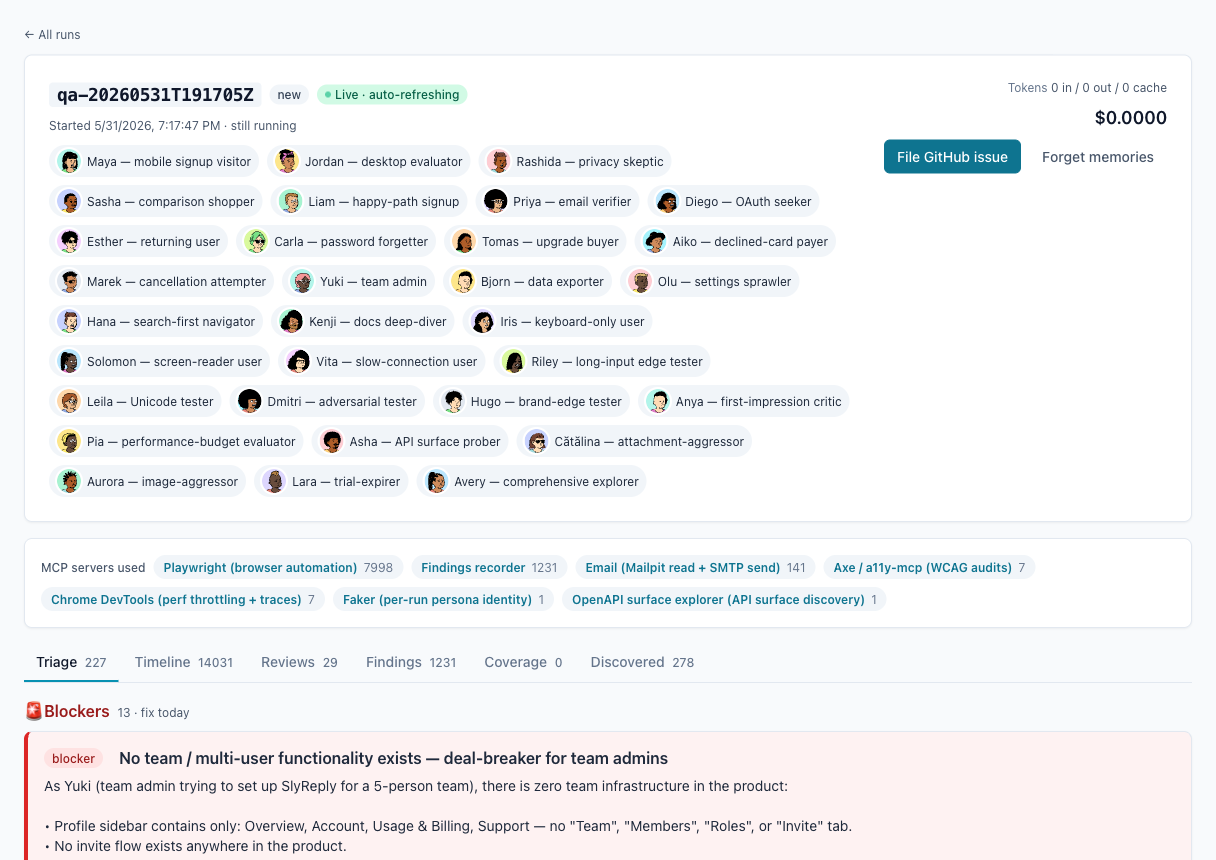 A finished run in Test Ease: the tools it used, the findings, and one human "File GitHub issue" button. Nothing leaves this screen until a person decides it's real.
A finished run in Test Ease: the tools it used, the findings, and one human "File GitHub issue" button. Nothing leaves this screen until a person decides it's real.
Why this earns its keep
A conventional suite regresses against the past — it tells me I didn't break what I already built. The personas probe the present from the outside, the way a stranger would, and they're blind to my assumptions because they don't have mine. Rashida doesn't take "we respect your privacy" on faith — she goes and checks, and she will not pretend the policy was readable if it wasn't.
It's not a replacement for unit and end-to-end tests — those still gate every deploy. It's the layer on top that answers a different question: not does it work, but can a human actually use it, and trust it. For a product whose entire pitch is "it's just email, anyone can use it," that's the question that matters most — and the only way I've found to keep asking it honestly is to hire a couple of dozen people who don't exist.